Publications
-
 In ACL 2026Yilun Zhu, Yuan Zhuang, Nikhita Vedula, Dushyanta Dhyani, Shaoyuan Xu, Moyan Li, Mohsen Bayati, Bryan Wang, and Shervin Malmasi
In ACL 2026Yilun Zhu, Yuan Zhuang, Nikhita Vedula, Dushyanta Dhyani, Shaoyuan Xu, Moyan Li, Mohsen Bayati, Bryan Wang, and Shervin MalmasiMany applications of LLM-based text regression require predicting a full conditional distribution rather than a single point value. We introduce Quantile Token Regression, which embeds dedicated quantile tokens directly into input sequences, enabling independent input-output pathways for each quantile through self-attention mechanisms. We augment these tokens with retrieval of semantically similar neighbor instances and their empirical distributions to ground predictions locally. We provide the first theoretical analysis of loss functions for quantile regression, clarifying which distributional objectives each optimizes. On benchmarks using LLMs from 1.7B to 14B parameters, our method achieves approximately 4 points lower MAPE and 2x narrower prediction intervals compared to baselines.
-
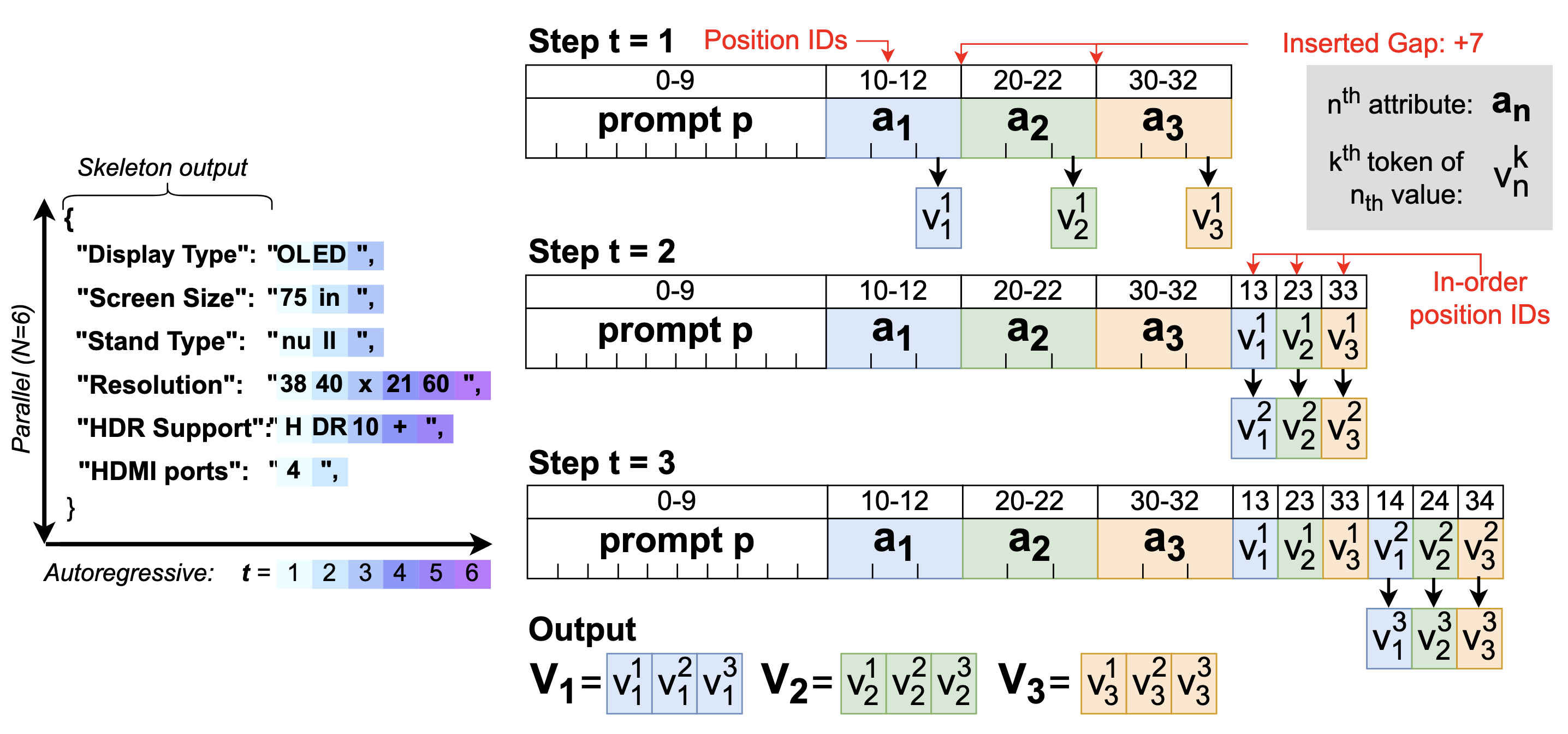 In Findings of ACL 2026Theodore Glavas, Nikhita Vedula, Dushyanta Dhyani, Yilun Zhu, and Shervin Malmasi
In Findings of ACL 2026Theodore Glavas, Nikhita Vedula, Dushyanta Dhyani, Yilun Zhu, and Shervin MalmasiSome text generation tasks, such as Attribute Value Extraction (AVE), require decoding multiple independent sequences from the same document context. While standard autoregressive decoding is slow due to its sequential nature, the independence between output sequences offers an opportunity for parallelism. We present Hyper-Parallel Decoding, a novel decoding algorithm that accelerates offline decoding by leveraging both shared memory and computation across batches. HPD enables out-of-order token generation through position ID manipulation, significantly improving efficiency. Experiments on AVE show that attribute-value pairs are conditionally independent, enabling us to parallelize value generation within each prompt. By further stacking multiple documents within a single prompt, we can decode in parallel up to 96 tokens per prompt. HPD works with all LLMs, and reduces both inference costs and total inference time by up to 13.8X without compromising output quality, potentially saving hundreds of thousands of dollars on industry AVE tasks.
-
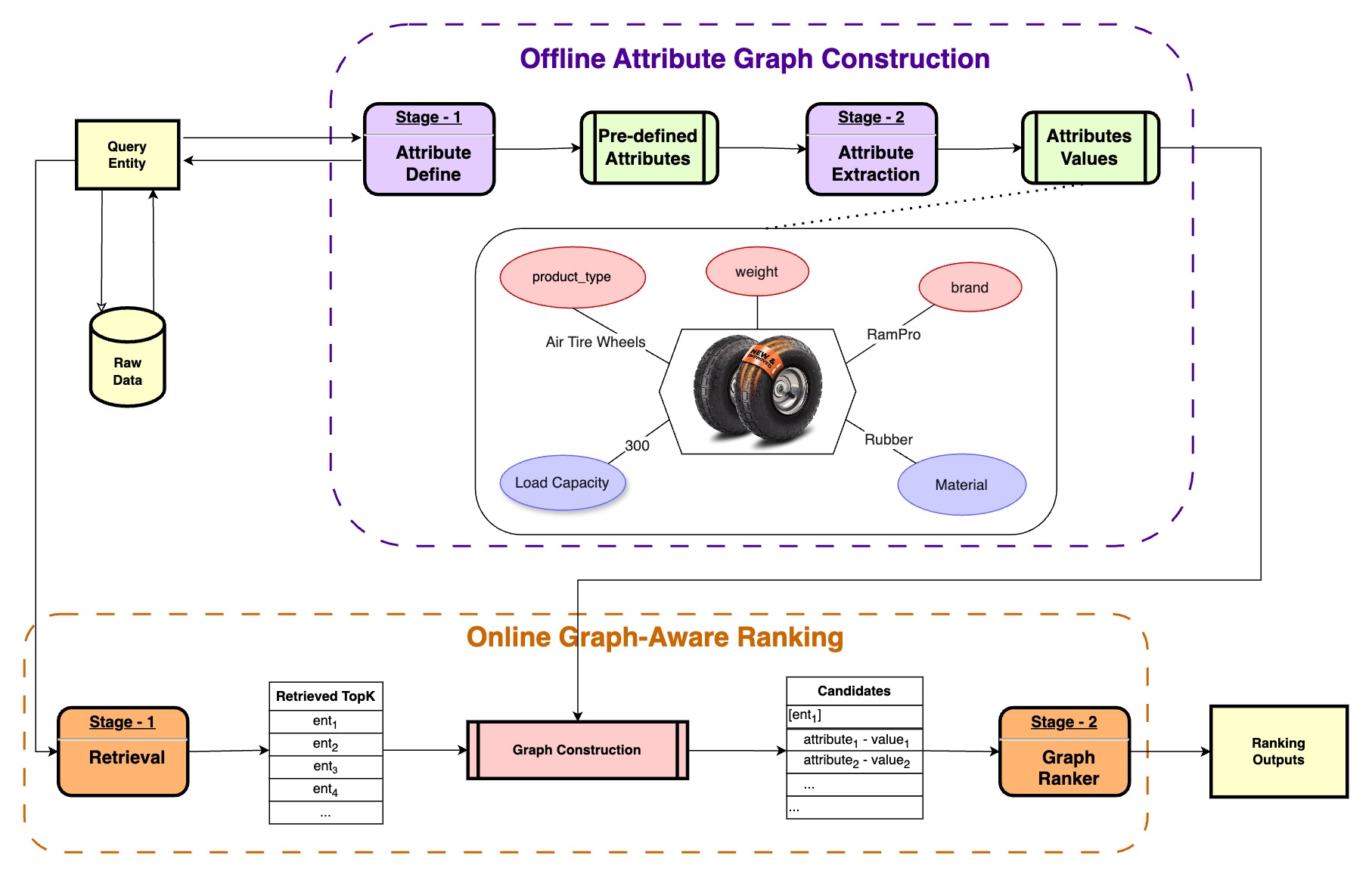 From Unstructured to Structured: LLM-Guided Attribute Graphs for Entity Search and RankingIn SIGIR 2026 Industry TrackYilun Zhu, Nikhita Vedula, and Shervin Malmasi
From Unstructured to Structured: LLM-Guided Attribute Graphs for Entity Search and RankingIn SIGIR 2026 Industry TrackYilun Zhu, Nikhita Vedula, and Shervin Malmasi -
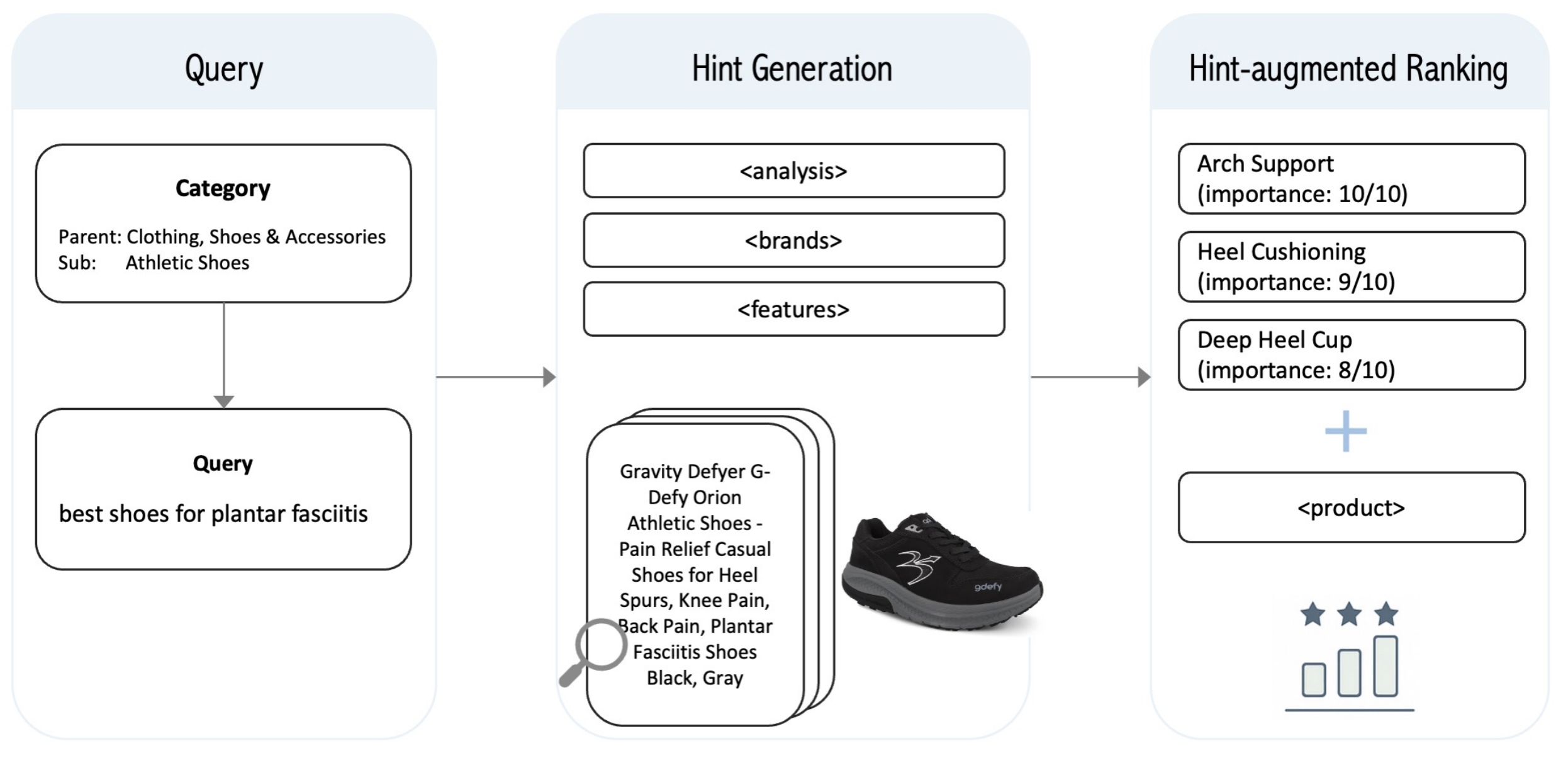 In IJCNLP-AACL 2025Yilun Zhu, Nikhita Vedula, and Shervin Malmasi
In IJCNLP-AACL 2025Yilun Zhu, Nikhita Vedula, and Shervin MalmasiSearch queries with superlatives (e.g., best, most popular) require comparing candidates across multiple dimensions, demanding linguistic understanding and domain knowledge. We show that LLMs can uncover latent intent behind these expressions in e-commerce queries through a framework that extracts structured interpretations or hints. Our approach decomposes queries into attribute-value hints generated concurrently with retrieval, enabling efficient integration into the ranking pipeline. Our method improves search performance by 10.9 points in MAP and ranking by 5.9 points in MRR over baselines. Since direct LLM-based reranking faces prohibitive latency, we develop an efficient approach transferring superlative interpretations to lightweight models. Our findings provide insights into how superlative semantics can be represented and transferred between models, advancing linguistic interpretation in retrieval systems while addressing practical deployment constraints.
-
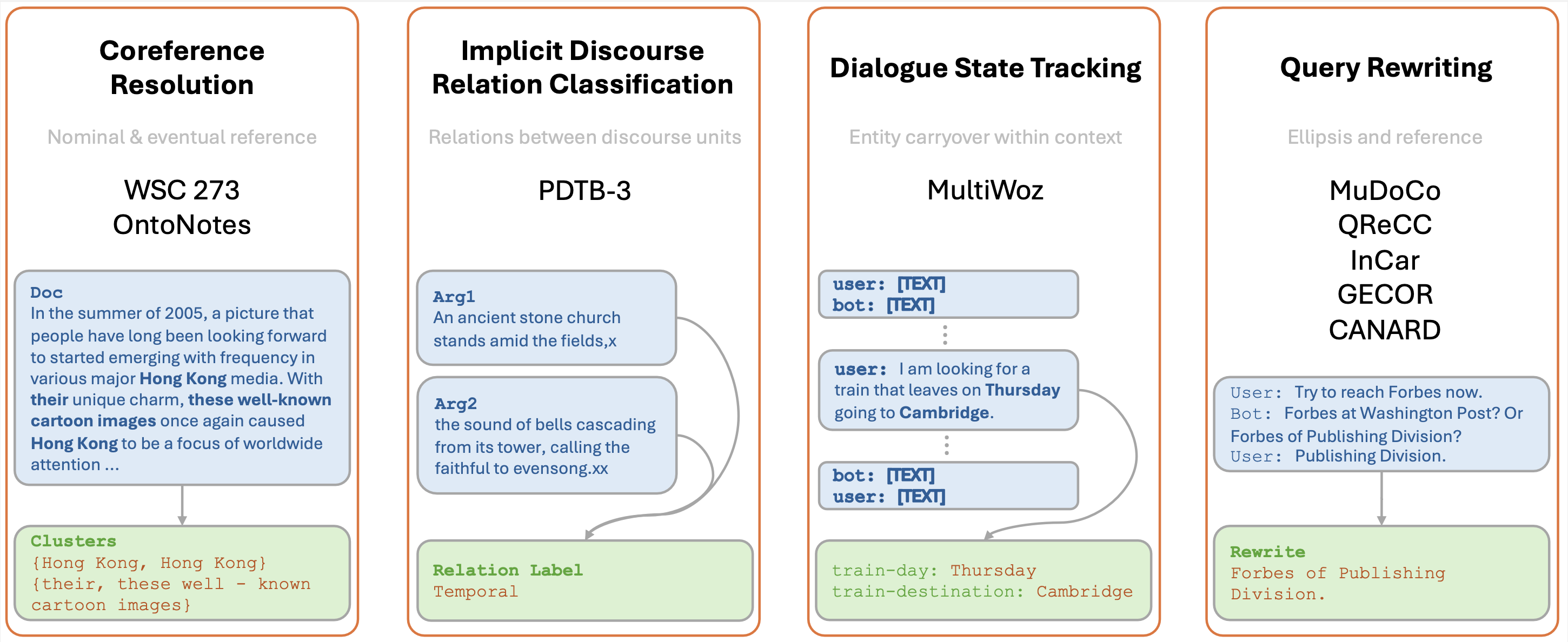 In Findings of EACL 2024Yilun Zhu, Joel Moniz, Shruti Bhargava, Jiarui Lu, Dhivya Piraviperumal, Site Li, Yuan Zhang, Hong Yu, and Bo-Hsiang Tseng
In Findings of EACL 2024Yilun Zhu, Joel Moniz, Shruti Bhargava, Jiarui Lu, Dhivya Piraviperumal, Site Li, Yuan Zhang, Hong Yu, and Bo-Hsiang TsengUnderstanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models’ ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
-
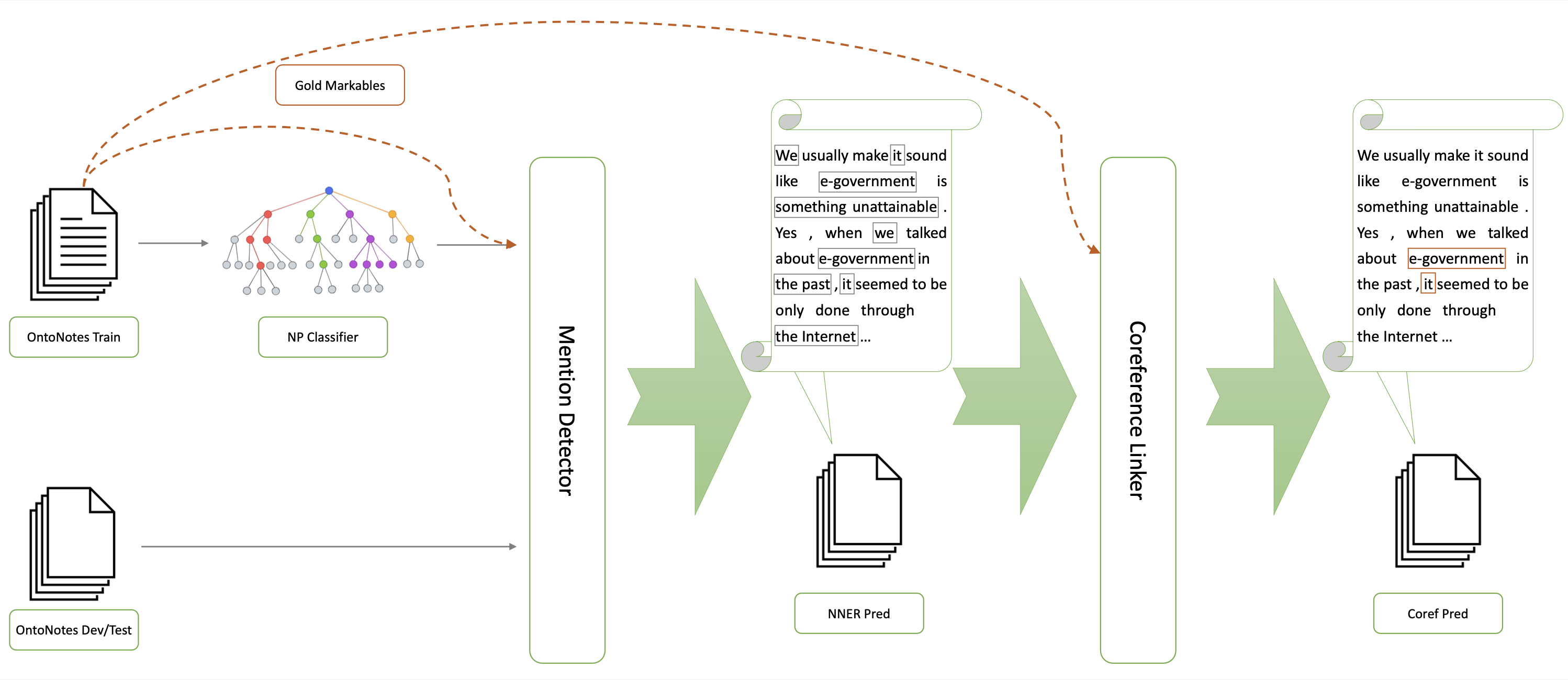 In LREC-COLING 2024Yilun Zhu, Siyao Peng, Sameer Pradhan, and Amir Zeldes
In LREC-COLING 2024Yilun Zhu, Siyao Peng, Sameer Pradhan, and Amir ZeldesSingleton mentions, i.e. entities mentioned only once in a text, are important to how humans understand discourse from a theoretical perspective. However previous attempts to incorporate their detection in end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention spans in the OntoNotes benchmark. This paper addresses this limitation by combining predicted mentions from existing nested NER systems and features derived from OntoNotes syntax trees. With this approach, we create a near approximation of the OntoNotes dataset with all singleton mentions, achieving ~94% recall on a sample of gold singletons. We then propose a two-step neural mention and coreference resolution system, named SPLICE, and compare its performance to the end-to-end approach in two scenarios: the OntoNotes test set and the out-of-domain (OOD) OntoGUM corpus. Results indicate that reconstructed singleton training yields results comparable to end-to-end systems for OntoNotes, while improving OOD stability (+1.1 avg. F1). We conduct error analysis for mention detection and delve into its impact on coreference clustering, revealing that precision improvements deliver more substantial benefits than increases in recall for resolving coreference chains.
-
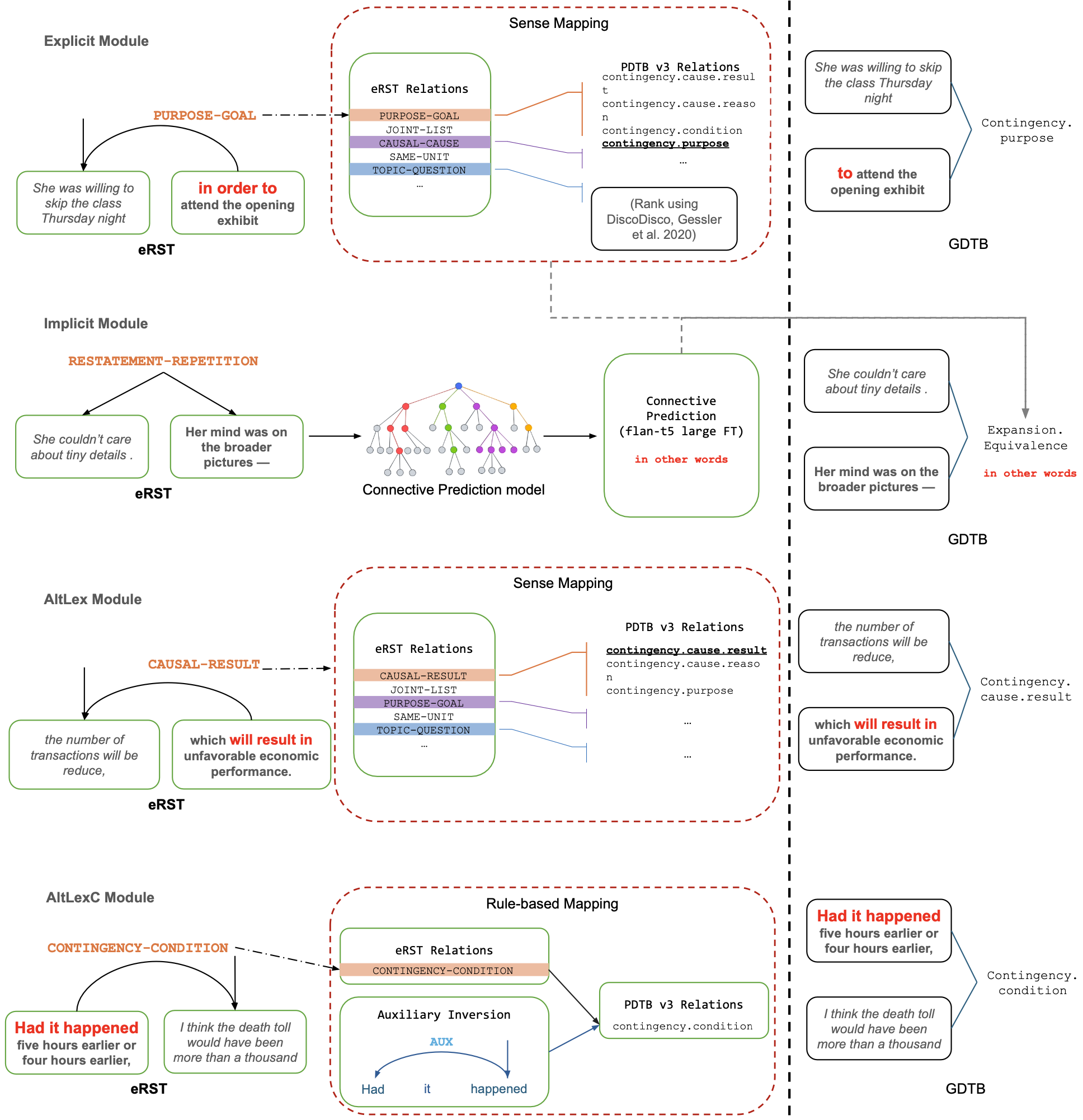 In EMNLP 2024Yang Janet Liu*, Tatsuya Aoyama*, Wesley Scivetti*, Yilun Zhu*, Shabnam Behzad, Lauren Elizabeth Levine, Jessica Lin, Devika Tiwari, and Amir Zeldes
In EMNLP 2024Yang Janet Liu*, Tatsuya Aoyama*, Wesley Scivetti*, Yilun Zhu*, Shabnam Behzad, Lauren Elizabeth Levine, Jessica Lin, Devika Tiwari, and Amir ZeldesWork on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
-
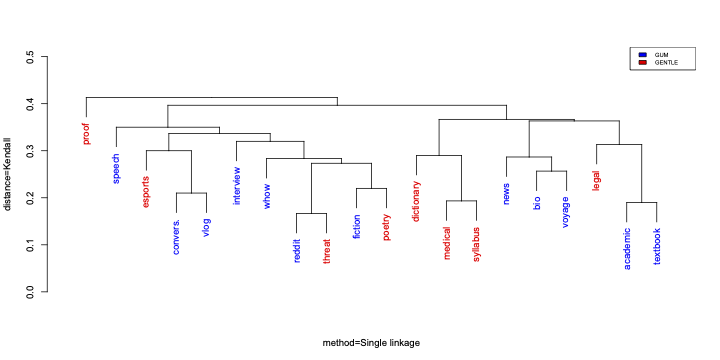 In LAW-XVII workshop @ ACL 2023Tatsuya Aoyama, Shabnam Behzad, Luke Gessler, Lauren Levine, Jessica Lin, Yang Janet Liu, Siyao Peng, Yilun Zhu, and Amir Zeldes
In LAW-XVII workshop @ ACL 2023Tatsuya Aoyama, Shabnam Behzad, Luke Gessler, Lauren Levine, Jessica Lin, Yang Janet Liu, Siyao Peng, Yilun Zhu, and Amir ZeldesWe present GENTLE, a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of-domain evaluation: dictionary entries, esports commentaries, legal documents, medical notes, poetry, mathematical proofs, syllabuses, and threat letters. GENTLE is manually annotated for a variety of popular NLP tasks, including syntactic dependency parsing, entity recognition, coreference resolution, and discourse parsing. We evaluate state-of-the-art NLP systems on GENTLE and find severe degradation for at least some genres in their performance on all tasks, which indicates GENTLE’s utility as an evaluation dataset for NLP systems.
-
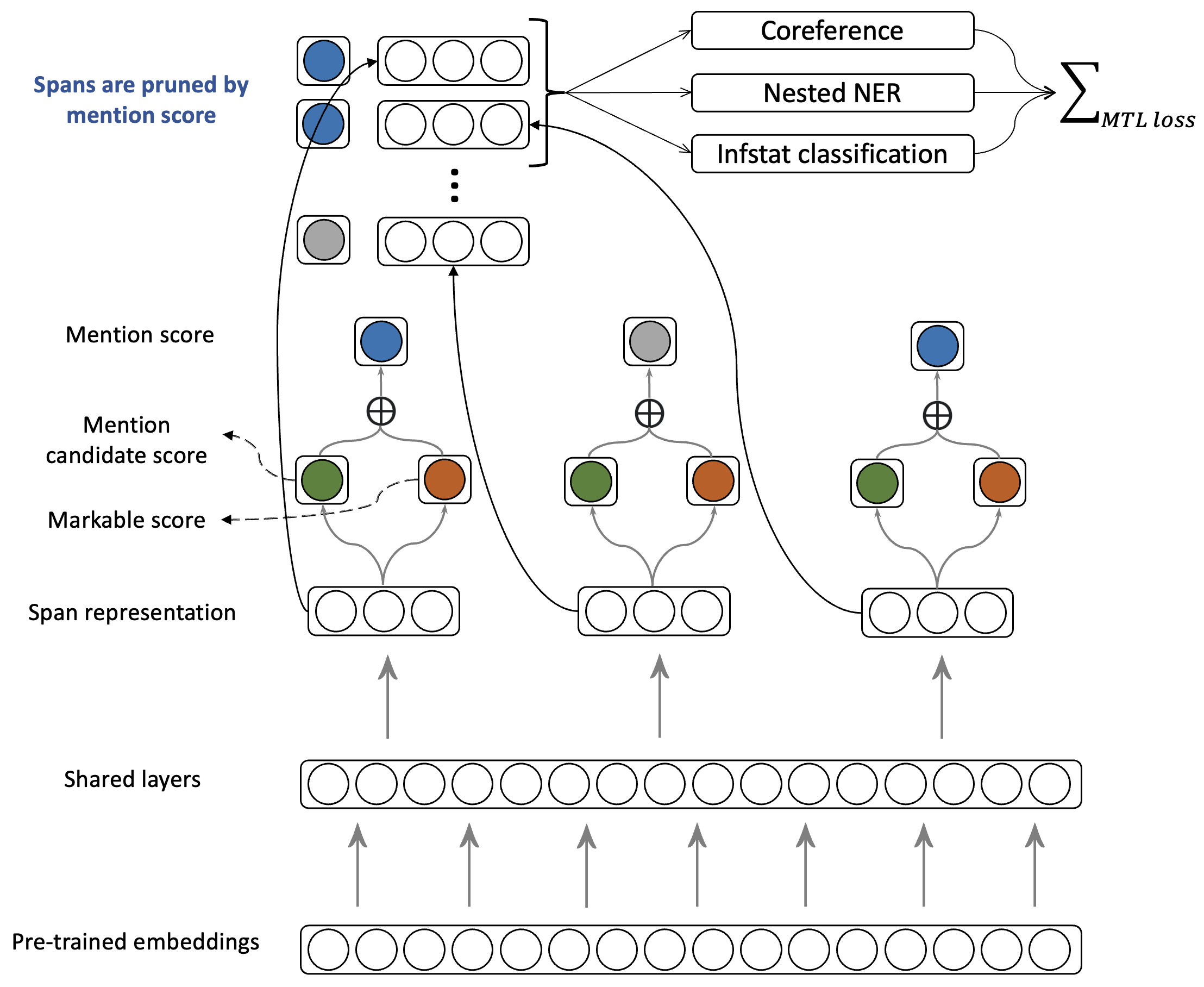 In IJCNLP-AACL 2023Yilun Zhu, Siyao Peng, Sameer Pradhan, and Amir Zeldes
In IJCNLP-AACL 2023Yilun Zhu, Siyao Peng, Sameer Pradhan, and Amir ZeldesPrevious attempts to incorporate a mention detection step into end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention span data as well as other entity information. This paper presents a coreference model that learns singletons as well as features such as entity type and information status via a multi-task learning-based approach. This approach achieves new stateof-the-art scores on the OntoGUM benchmark (+2.7 points) and increases robustness on multiple out-of-domain datasets (+2.3 points on average), likely due to greater generalizability for mention detection and utilization of more data from singletons when compared to only coreferent mention pair matching.
-
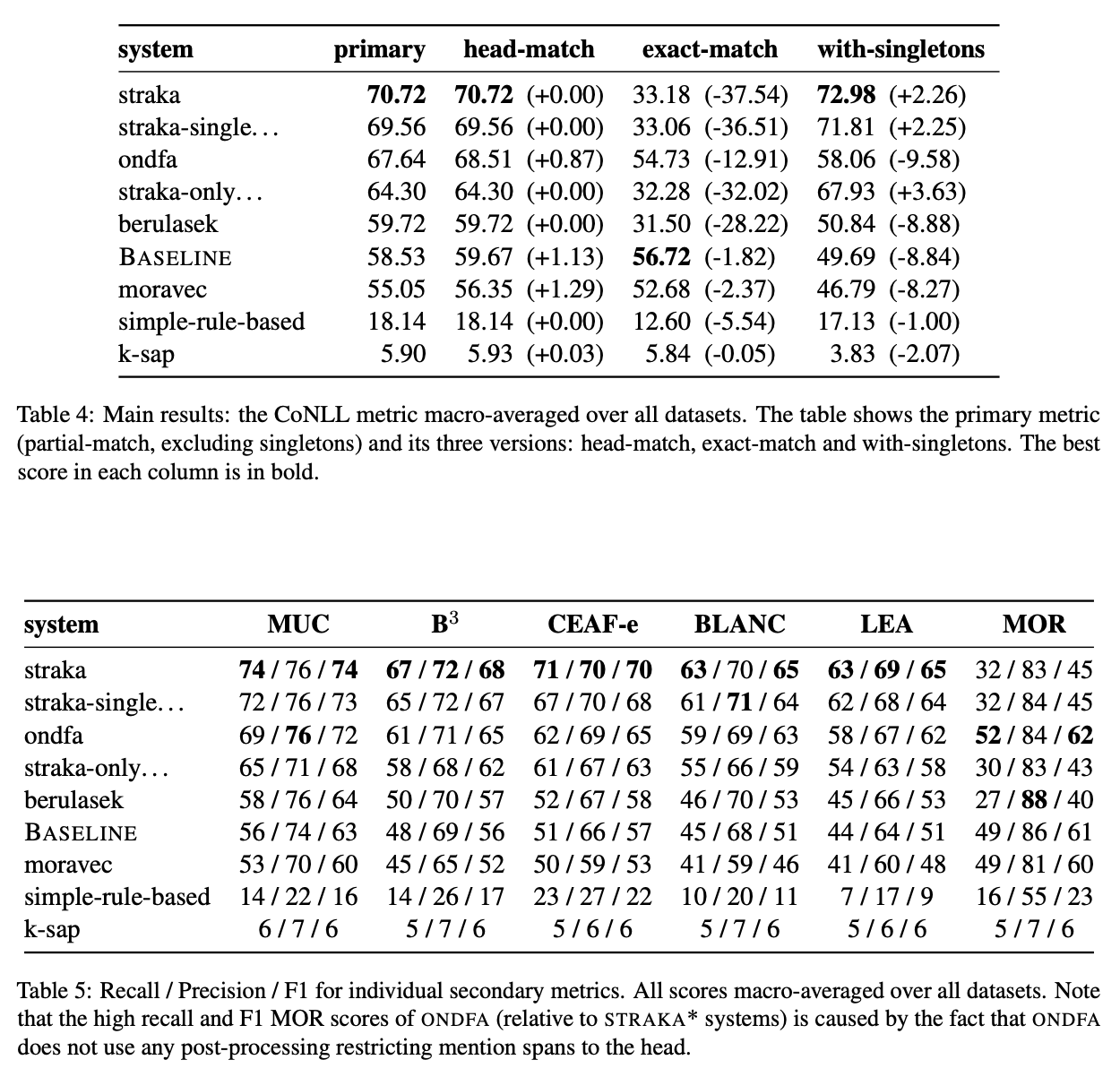 In CRAC workshop @ COLING 2022Zdeněk Žabokrtský, Miloslav Konopı́k, Anna Nedoluzhko, Michal Novák, Maciej Ogrodniczuk, Martin Popel, Ondřej Pražák, Jakub Sido, Daniel Zeman, and Yilun Zhu
In CRAC workshop @ COLING 2022Zdeněk Žabokrtský, Miloslav Konopı́k, Anna Nedoluzhko, Michal Novák, Maciej Ogrodniczuk, Martin Popel, Ondřej Pražák, Jakub Sido, Daniel Zeman, and Yilun ZhuThis paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
-
 In SCiL 2021Luke Gessler, Siyao Peng, Yang Liu, Yilun Zhu, Shabnam Behzad, and Amir Zeldes
In SCiL 2021Luke Gessler, Siyao Peng, Yang Liu, Yilun Zhu, Shabnam Behzad, and Amir Zeldes -
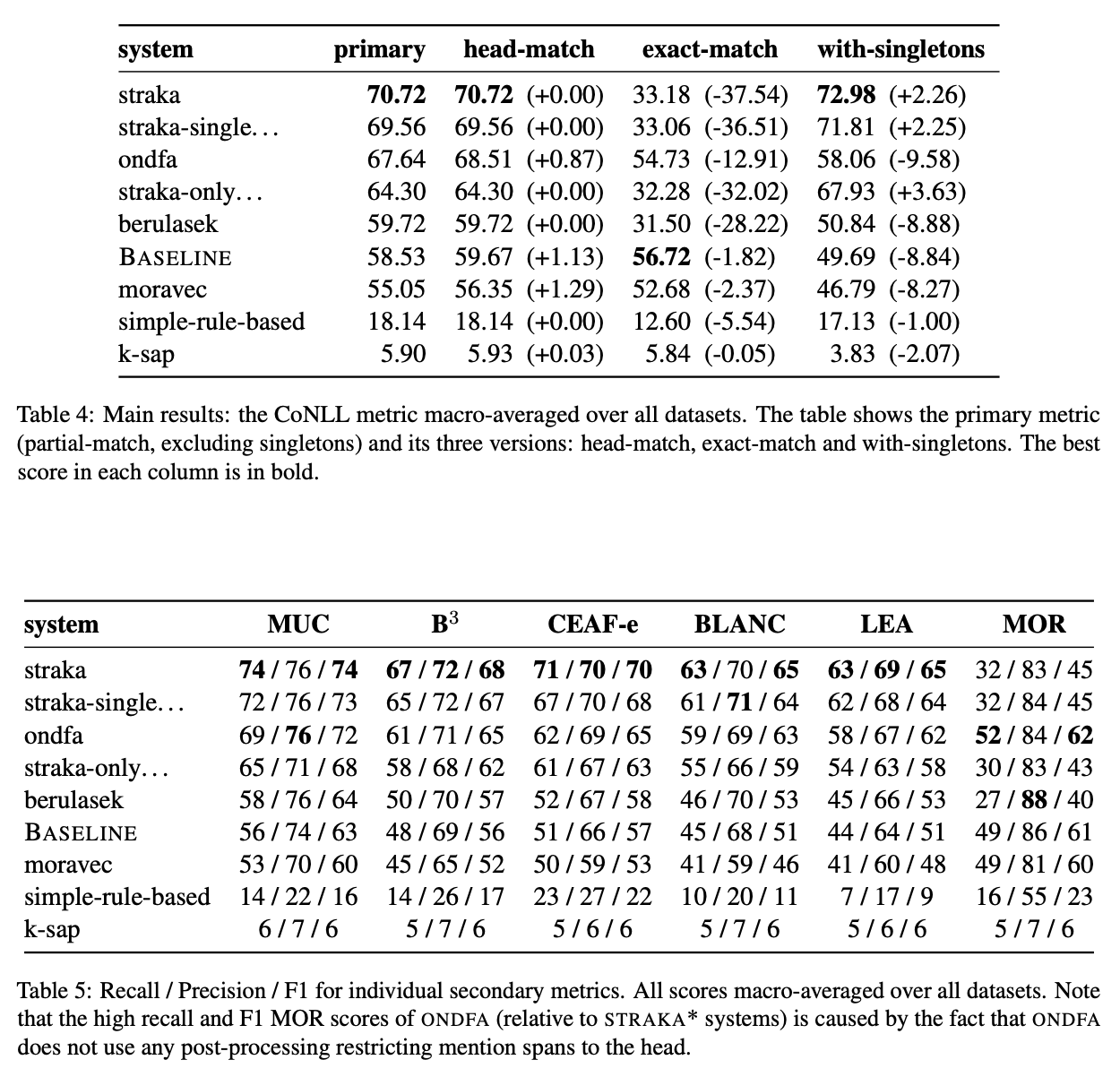 In ACL-IJCNLP 2021Yilun Zhu, Sameer Pradhan, and Amir Zeldes
In ACL-IJCNLP 2021Yilun Zhu, Sameer Pradhan, and Amir ZeldesSOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. This paper provides a dataset and comprehensive evaluation showing that the latest neural LM based end-to-end systems degrade very substantially out of domain. We make an OntoNotes-like coreference dataset called OntoGUM publicly available, converted from GUM, an English corpus covering 12 genres, using deterministic rules, which we evaluate. Thanks to the rich syntactic and discourse annotations in GUM, we are able to create the largest human-annotated coreference corpus following the OntoNotes guidelines, and the first to be evaluated for consistency with the OntoNotes scheme. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.
-
 In DISRPT workshop @ EMNLP 2021Luke Gessler, Shabnam Behzad, Yang Janet Liu, Siyao Peng, Yilun Zhu, and Amir Zeldes
In DISRPT workshop @ EMNLP 2021Luke Gessler, Shabnam Behzad, Yang Janet Liu, Siyao Peng, Yilun Zhu, and Amir ZeldesThis paper describes our submission to the DISRPT2021 Shared Task on Discourse Unit Segmentation, Connective Detection, and Relation Classification. Our system, called DisCoDisCo, is a Transformer-based neural classifier which enhances contextualized word embeddings (CWEs) with hand-crafted features, relying on tokenwise sequence tagging for discourse segmentation and connective detection, and a feature-rich, encoder-less sentence pair classifier for relation classification. Our results for the first two tasks outperform SOTA scores from the previous 2019 shared task, and results on relation classification suggest strong performance on the new 2021 benchmark. Ablation tests show that including features beyond CWEs are helpful for both tasks, and a partial evaluation of multiple pretrained Transformer-based language models indicates that models pre-trained on the Next Sentence Prediction (NSP) task are optimal for relation classification.
- In CRAC workshop @ EMNLP 2021Yilun Zhu, Sameer Pradhan, and Amir Zeldes
SOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. Zhu et al. (2021) introduced the creation of the OntoGUM corpus for evaluating geralizability of the latest neural LM-based end-to-end systems. This paper covers details of the mapping process which is a set of deterministic rules applied to the rich syntactic and discourse annotations manually annotated in the GUM corpus. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.
-
 In LREC 2020Siyao Peng, Yang Liu, Yilun Zhu, Austin Blodgett, Yushi Zhao, and Nathan Schneider
In LREC 2020Siyao Peng, Yang Liu, Yilun Zhu, Austin Blodgett, Yushi Zhao, and Nathan SchneiderAdpositions are frequent markers of semantic relations, but they are highly ambiguous and vary significantly from language to language. Moreover, there is a dearth of annotated corpora for investigating the cross-linguistic variation of adposition semantics, or for building multilingual disambiguation systems. This paper presents a corpus in which all adpositions have been semantically annotated in Mandarin Chinese; to the best of our knowledge, this is the first Chinese corpus to be broadly annotated with adposition semantics. Our approach adapts a framework that defined a general set of supersenses according to ostensibly language-independent semantic criteria, though its development focused primarily on English prepositions (Schneider et al., 2018). We find that the supersense categories are well-suited to Chinese adpositions despite syntactic differences from English. On a Mandarin translation of The Little Prince, we achieve high inter-annotator agreement and analyze semantic correspondences of adposition tokens in bitext.
- In LREC 2020Luke Gessler, Siyao Peng, Yang Liu, Yilun Zhu, Shabnam Behzad, and Amir Zeldes
We present a freely available, genre-balanced English web corpus totaling 4M tokens and featuring a large number of high-quality automatic annotation layers, including dependency trees, non-named entity annotations, coreference resolution, and discourse trees in Rhetorical Structure Theory. By tapping open online data sources the corpus is meant to offer a more sizable alternative to smaller manually created annotated data sets, while avoiding pitfalls such as imbalanced or unknown composition, licensing problems, and low-quality natural language processing. We harness knowledge from multiple annotation layers in order to achieve a “better than NLP” benchmark and evaluate the accuracy of the resulting resource.
- In SCiL 2019Yilun Zhu, Yang Janet Liu, Siyao Peng, Austin Blodgett, Yushi Zhao, and Nathan Schneider
This study adapts Semantic Network of Adposition and Case Supersenses (SNACS) annotation to Mandarin Chinese and demonstrates that the same supersense categories are appropriate for Chinese adposition semantics. We annotated 15 chapters of The Little Prince, with high interannotator agreement. The parallel corpus gives insight into differences in construal between the two languages’ adpositions, namely a number of construals that are frequent in Chinese but rare or unattested in the English corpus. The annotated corpus can further support automatic disambiguation of adpositions in Chinese, and the common inventory of supersenses between the two languages can potentially serve cross-linguistic tasks such as machine translation.
-
 In DISRPT workshop @ NAACL 2019Yue Yu, Yilun Zhu, Yang Liu, Yan Liu, Siyao Peng, Mackenzie Gong, and Amir Zeldes
In DISRPT workshop @ NAACL 2019Yue Yu, Yilun Zhu, Yang Liu, Yan Liu, Siyao Peng, Mackenzie Gong, and Amir ZeldesIn this paper we present GumDrop, Georgetown University’s entry at the DISRPT 2019 Shared Task on automatic discourse unit segmentation and connective detection. Our approach relies on model stacking, creating a heterogeneous ensemble of classifiers, which feed into a metalearner for each final task. The system encompasses three trainable component stacks: one for sentence splitting, one for discourse unit segmentation and one for connective detection. The flexibility of each ensemble allows the system to generalize well to datasets of different sizes and with varying levels of homogeneity.